SLAM Literature Review
Literature review for SLAM papers.
Overview
Past, Present, and Future of Simultaneous Localization and Mapping- Toward the Robust-Perception Age
- Architecture
- Sensor-depended Frontend extracts meaningful data from raw sensor measurements, perform data association, and get initial estimate of current state
- Backend performs MAP (converting to least square optimization with sparsity in normal equations) on extracted data from frontend, to achieve high accuracy
- Loop closure detection helps to resolve the drift over long period of time / large space
- Robustness
- Wrong data association, wrong loop closure detection could cause SLAM failures
- SLAM needs to be robust to wrong estimation, be able to recover quickly from failures, and even foresee imminent failures
- Scalability
- Large area, long time exploration will add unbounded number of states into SLAM system, leading it impossible to solve
- SLAM needs to be limit the number of states by abstracting hyperinfo from states, using submap to temporarily offload states, and use multi-agent setup to split the cost
- Metric map representation
- Current types
- Landmark-based spare points
- Dense point cloud
- Boundary and spatial-partitioning dense (TSDF functions etc)
- Object-based, using primitive shapes with operations to represent a real object
- SLAM needs to use high-level expressed map presentation to save memory & compute, to improve robustness and scalability. However, the optimal representation for geometry shapes still needs to be researched
- Current types
- Semantic map representation
- To enhance SLAM, semantic meaning needs to be associated with geometric map. Semantic could be coarse and fine, and could be hierarchy
- There are works to do semantic classification post SLAM, using semantic knowledge to help for SLAM, or joint SLAM and semantic inferencing, but it still lack of research for how to consistently fuse semantic and metric info, or how to leverage the semantic info to do smarter tasks
- Theoretical progress
- Consistency and observability analysis for filter approach
- When strong duality holds, factor graph optimization can be solved globally. Without strong duality, the optimization needs an accurate initial value to solve
- Active SLAM
- Compute the utility of possible action, select and execute the action with larger benefit
Data Association
SuperPoint: Self-Supervised Interest Point Detection and Description
Extract feature points with DNN model
- Generating synthetic dataset with basic shapes and known corner points
- Train MagicPoint model (base model)
- Soft labeling real dataset with Homography Adaption
- Train final SuperPoint model (final model)
SuperPoint model consists of 1 encoder, 1 decoder providing the probability as a keypoint for each pixel, and 1 decoder providing descriptor for each pixel.
Optimization
Decoupled, consistent node removal and edge sparsification for graph-based SLAM
Discussed in details how to perform the marginalization for sliding window SLAM, and how to keep the sparsity of the problem. See more notes in this post.
A Consistent Parallel Estimation Framework for Visual-Inertial SLAM
Discussed about how to keep the consistency for estimations across multi-thread of tracking and mapping.
Loop Closure
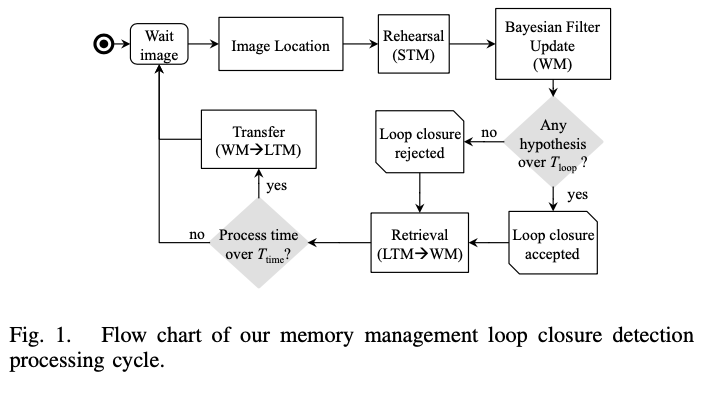
Memory Management for Real-Time Appearance-Based Loop Closure Detection
Proposed a backend architecture to manage frame scale, and to achieve loop closure detection under fixed time.
- Introduced short-term memory (STM, stores latest image locations), working memory (WM, used to detect loop closure with new image location), and long-term memory (LTM, stores more previous frames, stored in disk and could be retrieved and updated)
- When a new frame comes in, it needs to perform following steps
- Extract visual words according to local feature descriptors. Create “location” with weight=0 and a link with previous location. This frame is in STM
- Merge the closest previous location within STM with current location. Update the weights and link of current location
- Calculate posterior probability between current location with previous locations inside WM
- Select the location $L_i$ with highest probability from WM, and check if it’s higher than loop threshold
- Retrieve neighbor locations of $L_i$ (no matter whether if $L_i$ is loop closure) from LTM, update visual dictionary
- If the process time is larger than threshold, convert location with lowest weight from WM to LTM
3D Reconstruction
SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
Proposed deep-learning based method to perform 3D reconstruction from video sequence without estimating frame poses and camera parameters
- Middle frame from the clip will be treated as keyframe
- I2P (Image to Points) model: output 3D points from a video clip (a sliding window of original video)
- multi-branch ViT (Visual Transformer)
- Input: frames from a clip with 1 frame as keyframe
- Output: features of each frame, 3D points reconstructed and their confidence
- Model structure
- Encoder: encode each frame from the clip to features
- Keyframe Decoder: self-attention for keyframe features, cross-attention for keyframe features v.s. all supporting frames’ features
- Supporting Decoder: cross-attention for each supporting frame’s features v.s keyframe features
- Buffering set
- Hold up to
Bregistered frames / scene frames for global reconstruction - When a new keyframe after I2P, it may be treated as a scene frame. If chosen as scene frame, it will be inserted into buffering set and replace one of the current frame
- When a new scene keyframe comes, its features will be fed into a retrieval model to compute correlation score v.s. each of other scene frame in the buffering set. The top-
Kbest-correlated keyframes will be selected as global reference to fuse the current scene keyframe
- Hold up to
- L2W (Local to World) model: incrementally register local point clouds to the global point cloud
- Input: K scene frames and a new keyframes with their features and 3D points from I2P
- Output: new (transformed) 3D points in global reference frame
- Model structure
- Points embedding: encode 3D points from each scene frame into (geometric) features. Combine with visual features from I2P for each scene frame
- Registration decoder: self-attention for keyframe features (visual + geometric), cross-attention for keyframe features v.s. all scene features
- Scene decoder: cross-attention for each scene features v.s. keyframe features